Mastering Decision Trees and Random Forests in Machine Learning
Written on
Introduction to Decision Trees and Random Forests
In this piece, we will explore two pivotal algorithms in machine learning: Decision Trees and Random Forests. Our aim is to illustrate how to construct a Decision Tree manually with basic tools, and subsequently extend this concept to build a Random Forest model.
Understanding the Dataset
To put theory into practice, let's utilize a straightforward dataset.
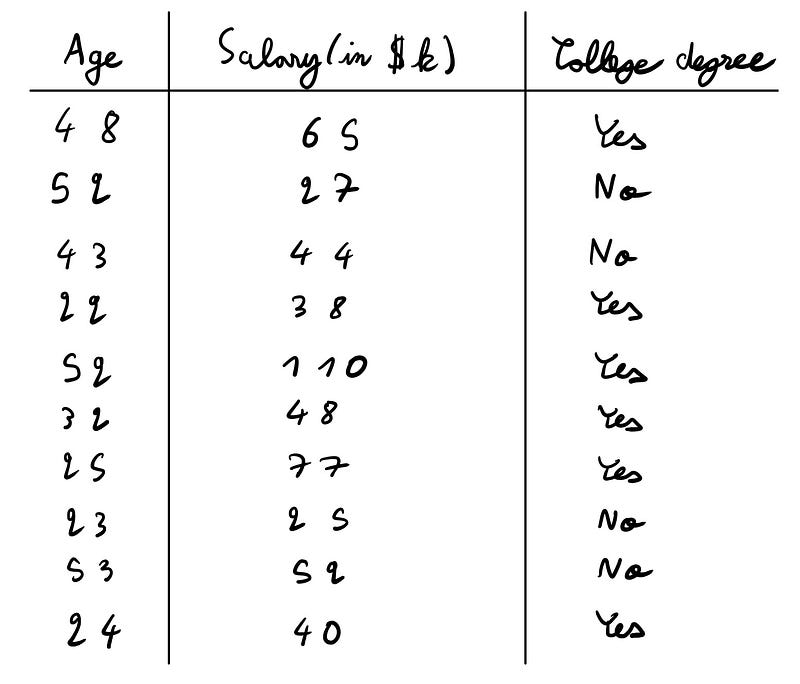
In this scenario, we are attempting to ascertain whether an individual possesses a college degree based on two numerical factors: age and salary (expressed in thousands of dollars).
Initial Hypotheses about the Dataset
When confronted with a new dataset, forming preliminary hypotheses is a beneficial exercise. Here are my two assumptions regarding this data:
- Individuals with higher salaries are likely to have a college degree, as many high-paying professions (such as medicine, law, tech, consulting, and finance) typically require a degree.
- Younger individuals tend to pursue higher education more than older generations, a trend supported by research from the Pew Research Center and personal observations.
Upon analyzing the data, I discovered that the average age of those with a college degree is 34 years, while those without one average 43 years. Additionally, college graduates earn an average salary of $63,000 compared to $37,000 for non-graduates. These findings validate both of my hypotheses.
Building a Decision Tree
Next, let's delve into how we can train a Decision Tree using this dataset to generate predictions.
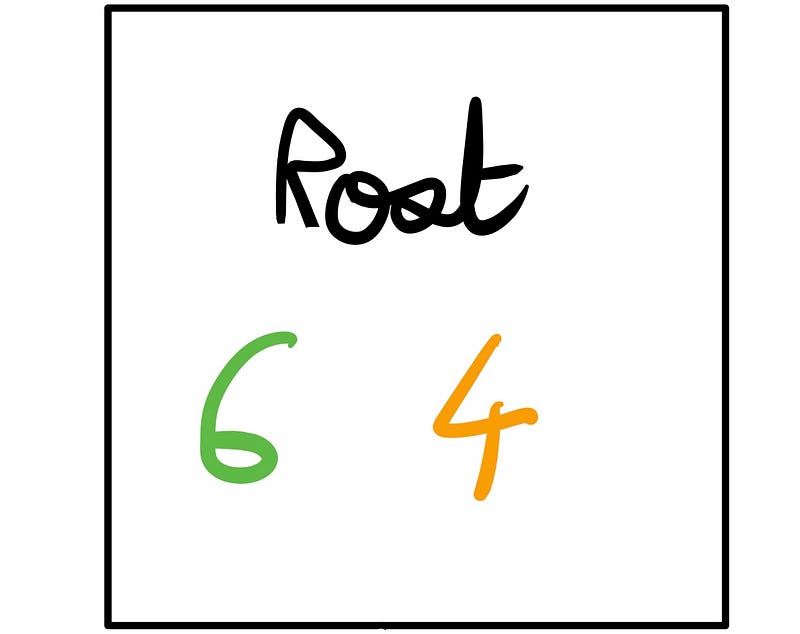
Initially, our dataset consists of 6 affirmative (Yes) and 4 negative (No) responses, establishing our root node. Throughout the decision-making process, we will always know the true classifications, which is crucial for the next steps.
At each node of the tree, we can predict one of the classes. If we predict "Yes," we classify 6 out of the 10 correctly, resulting in an error rate of 40%. Conversely, predicting "No" yields a 60% error rate. Therefore, to minimize errors, the prediction should be "Yes."
However, we can enhance our predictions by utilizing features from our dataset.
Making Splits
To improve our predictions, we can establish a threshold: if an individual's salary exceeds a certain amount, we predict "Yes"; otherwise, we predict "No." Let's illustrate this with an example:
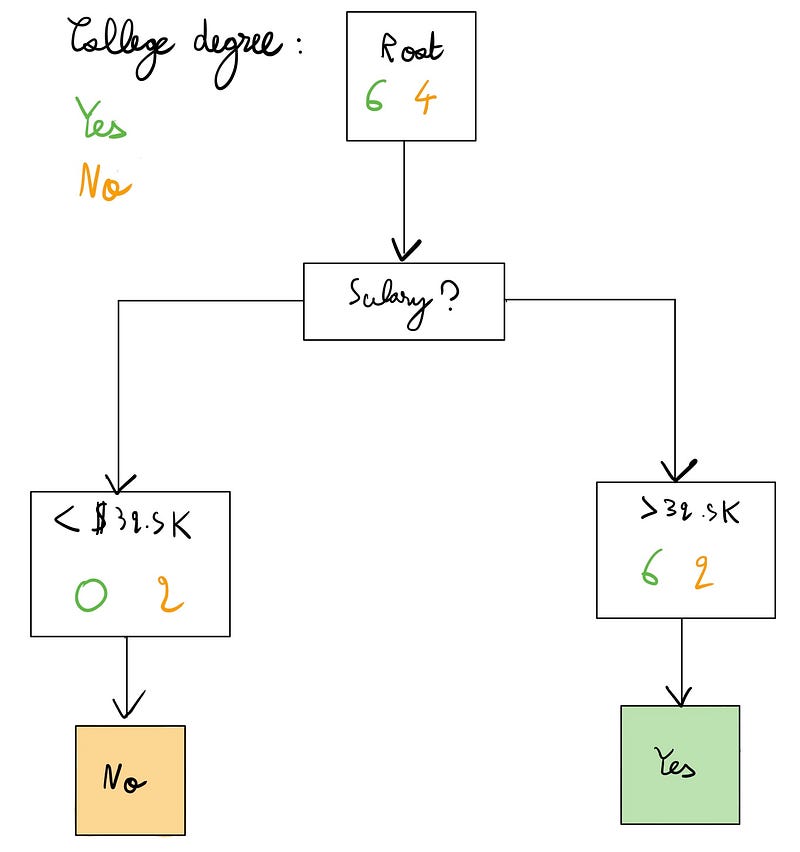
In the diagram, we introduce a split based on a salary threshold of $32,500, which turns out to be the optimal split. This adjustment lowers our error rate to 20%, with only two misclassifications.
Determining the Best Threshold
To identify the most effective threshold, we can follow this method:
- Order the feature values (in this case, salaries).
- Calculate the midpoint between each pair of values.
- Use these midpoints as potential threshold values and assess the corresponding loss.
- Select the threshold with the lowest error rate.
For instance:

In this analysis, choosing a threshold of 42K yields an error rate of 40%. Therefore, we return to our previous threshold of 32.5K, which was the most effective.
Choosing Variables for Splits
Now that we have determined the optimal threshold for salary, we need to decide whether to split based on age or salary for the next step. We compute the error rates for age in the same manner and select the feature with the lowest error rate.
After evaluating all possible splits:
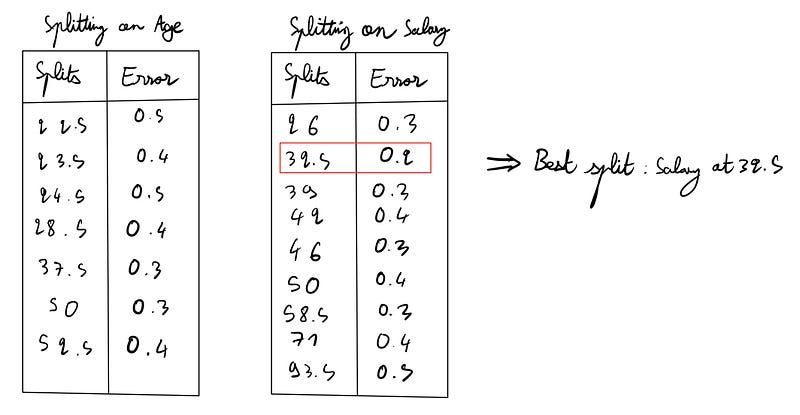
We find that splitting based on salary at 32.5K yields a lower error rate than age (20% vs. 30%). Thus, we proceed with this split.
Continuing the Process
We can continue this process recursively, splitting the dataset until we either reach zero errors or exhaust our features. The resulting tree structure will look like this:
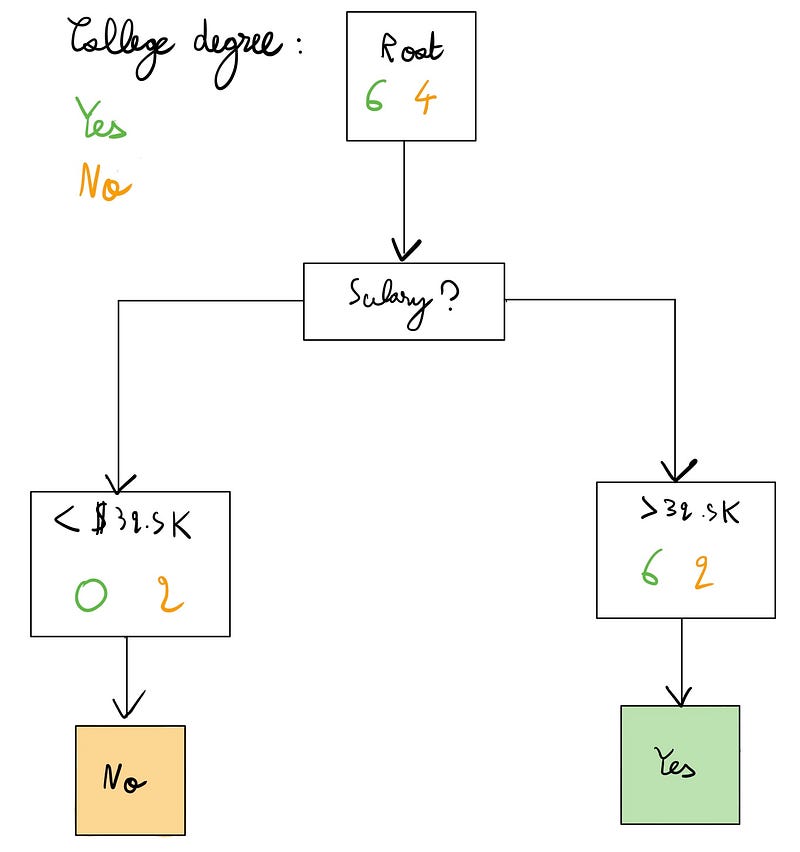
On the left side, we have achieved perfect classification and do not need further splits. Conversely, the right side still allows for further refinement.
Working with Categorical Features
If you are dealing with categorical features rather than numerical ones, the splitting process remains largely unchanged. You simply assess the performance of the splits based on the available categorical values.
When to Cease Tree Growth?
In practice, datasets often contain numerous features, allowing for extensive tree growth. However, this introduces the bias-variance trade-off, where deeper trees may better fit the dataset but risk overfitting.
Two common strategies to manage tree growth are early stopping and pruning. Early stopping involves halting further splits based on specific conditions, while pruning entails constructing a more complex tree first and then removing certain nodes based on conditions.
Building a Random Forest
Now, let’s discuss how to create a Random Forest classifier. The process is straightforward:
- Generate a number of Decision Trees.
- Randomly sample from your dataset (with replacement) for each tree.
- Train each Decision Tree on its corresponding sample.
Once you have a collection of Decision Trees, you will employ a majority vote mechanism for predictions. For instance, if 64 out of 100 trained trees predict "Yes" for an instance, the final prediction will be "Yes."
Conclusion
This overview has provided a foundational understanding of Decision Trees and Random Forests. While we have not covered certain advanced topics, such as various split metrics or regression applications, this framework serves as a solid starting point for those new to these algorithms.
I encourage you to replicate the calculations on paper to solidify your understanding. Additionally, I have explored concepts such as Ridge and Lasso, which can enhance your grasp of the bias-variance trade-off relevant to Decision Trees.
I hope you found this tutorial informative! Feel free to reach out on LinkedIn or GitHub for further discussions about Data Science and Machine Learning.
Random Forest in Python - Machine Learning From Scratch
This video tutorial guides you through implementing the Random Forest algorithm in Python, detailing each step for clarity.
Decision Tree Classification in Python (from scratch!)
Explore this video for a comprehensive guide on building a Decision Tree from the ground up in Python.