Understanding the Constraints of AWS Glue Job Bookmarks
Written on
Chapter 1: Introduction to AWS Glue
AWS Glue serves as a serverless solution primarily designed for executing extract, transform, and load (ETL) processes. It allows data practitioners to utilize its capabilities without needing in-depth knowledge of cluster architecture. At its core, AWS Glue leverages Apache Spark, accessible via the Python PySpark API or Scala. It facilitates the movement and cataloging of large datasets, whether through Glue crawlers or code-based approaches, enabling the addition of new data partitions, tables, and databases. Glue jobs can source data from platforms like Amazon RDS and Amazon S3 while targeting others, such as Amazon Redshift. By utilizing Glue, data experts can create comprehensive workflows to orchestrate data-driven pipelines, employing infrastructure as code (IaC) tools like Terraform and AWS CloudFormation, along with seamless integration through AWS CodeBuild and AWS CodePipeline.
Chapter 1.1: Glue Job Bookmarks Explained
Data practitioners can opt for either full or incremental data loading methods. Incremental data loading is particularly beneficial for large and continuously growing datasets, often seen in transactional databases as businesses expand. Conversely, full data loading is suitable for smaller datasets that are easy to synchronize. Job bookmarks can be configured to monitor which data has already been processed during ETL for incremental loads. Moreover, developers can implement code-based solutions to track changes in job source records. Fortunately, setting up bookmarks through Glue's job configuration is straightforward.
Section 1.1.1: Code Configuration for Job Bookmarks
To configure bookmarks at the code level, one must include “job.init” at the beginning, “job.commit()” at the end, and specify “transformation_ctx” for the various stages of the job, along with “jobBookmarkKeys” and “jobBookmarkKeysSortOrder” when invoking the source.
#!/usr/bin/env python
# -- coding: utf-8 --
# Importing libraries
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
# Params configuration
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# Data source
datasource0 = glueContext.create_dynamic_frame
.from_catalog(database="database",
table_name="relatedqueries_csv",
transformation_ctx="datasource0",
additional_options={"jobBookmarkKeys":["col0"],
"jobBookmarkKeysSortOrder":"asc"})
# Data entries map
applymapping1 = ApplyMapping.apply(frame=datasource0,
mappings=[("col0", "long", "id", "long"),
("col1", "string", "number", "string"),
("col2", "string", "name", "string")
],
transformation_ctx="applymapping1")
# Data target
datasink2 = glueContext.write_dynamic_frame
.from_options(frame=applymapping1,
connection_type="s3",
connection_options={"path": "s3://input_path"},
format="json",
transformation_ctx="datasink2")
job.commit()
Section 1.2: Configuring Job Properties
Bookmarks can be activated by adjusting job properties in the AWS Glue console, as depicted in the accompanying image.

Chapter 2: Challenges with AWS Glue Job Bookmarks
In the first video, you will learn about utilizing job bookmarks in AWS Glue jobs, providing insights into best practices for effective implementation.
The second video explains what job bookmarks are in AWS Glue, detailing their purpose and advantages.
Bookmark Limitations
While AWS Glue offers robust functionalities, it is not without limitations. From my practical experience, I have encountered challenges when working with AWS Glue job bookmarks, and I aim to share my insights to help others avoid similar frustrations.
Using JDBC Connections
As previously mentioned, Glue jobs can source data from various repositories, with Amazon RDS and Amazon S3 being common choices. Bookmarks function effectively when ingesting data from files or objects stored in S3 buckets, regardless of whether records are new or have been updated since the last job execution. However, when jobs source data from RDS-hosted transactional databases, bookmarks may not capture records that have been modified post the last job run, even if they were initially captured.
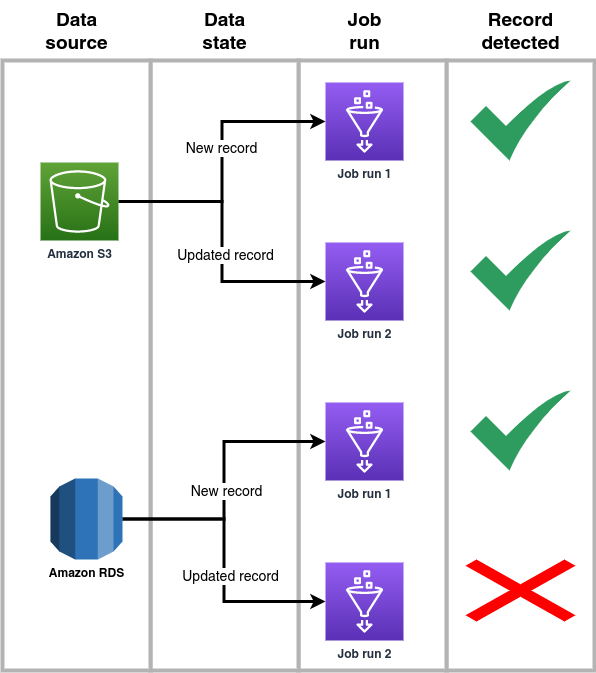
Addressing this issue is straightforward, considering that AWS Glue operates on Spark. For instance, if a job reads from the “projects” table in an RDS database, which includes a timestamp field like “updated_at” that updates with each record modification, this field can serve as our incremental data load bookmark. We can create a Python function, like the one below, to check the last job run timestamp stored in a JSON file in the S3 bucket "my-ancillary-bucket" and formulate a SQL statement that filters records based on the bookmark.
#!/usr/bin/env python
# -- coding: utf-8 --
# Importing libraries
import boto3
import datetime
import json
import botocore
def checkingLastJobRunning(FileKey, jobBookmarkKeys):
'''
Function to check the last running date for the Glue job
Args:
- FileKey (string): Key for the object in S3 containing the last run timestamp
- jobBookmarkKeys (string): Name for the job bookmark key
Output:
- FilterStatement (string): Query statement
'''
# Checking current running timestamp
now_timestamp = datetime.datetime.utcnow()
.strftime("%Y-%m-%d %H:%M:%S.%f")to_json = {
'previous_timestamp': now_timestamp}
# Create a S3 client
s3 = boto3.resource('s3')
# Checking last running timestamp for the job
try:
content_object = s3.Object('my-ancillary-bucket', FileKey)
file_content = content_object.get()['Body'].read().decode('utf-8')
json_content = json.loads(file_content)
previous_timestamp = json_content['previous_timestamp']
symbol = '>'
except botocore.exceptions.ClientError:
previous_timestamp = now_timestamp
symbol = '<='
# Save new run timestamp
s3.Bucket('my-ancillary-bucket').put_object(Key=FileKey,
Body=(bytes(json.dumps(to_json).encode('utf-8'))))
# Filter statement
FilterStatement = f"WHERE {jobBookmarkKeys} ::timestamp {symbol} '{previous_timestamp}' :: timestamp"
return FilterStatement
Now, the above function can be utilized to formulate the SQL query that filters records from the "projects" table. By leveraging a JDBC connection and a Spark session (using a PostgreSQL driver in this example), a Spark DataFrame can be created containing entries made or altered since the last job execution.
#!/usr/bin/env python
# -- coding: utf-8 --
# Importing libraries
import sys
from pyspark.conf import SparkConf
from pyspark.context import SparkContext
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from awsglue.job import Job
# Add additional spark configurations
conf = SparkConf() Any additional spark configuration you need --------------------------------------------------------
# Initial configuration
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
glueContext = GlueContext(SparkContext.getOrCreate(conf=conf))
sparkSession = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# Checking filter statement
filter_statement = checkingLastJobRunning('my-previous-job-run.json',
'updated_at')
# RDS table to query
tablename = "projects"
# Data source
datasource0 = sparkSession.read.format("jdbc").
options(
url=f'jdbc:postgresql://{DB_HOST}:{DB_PORT}/{DB_NAME}',
dbtable=f"(SELECT * FROM {tablename} {filter_statement}) as subquery",
user=DB_USER,
password=DB_PASSWORD,
driver='org.postgresql.Driver').
load()
Maximum Size Constraints for Bookmarks
One notable limitation with Glue bookmarks is the maximum state size, which is capped at 400 KB. If you encounter an error message such as:
com.amazonaws.services.gluejobexecutor.model.InvalidInputException: Entity size has exceeded the maximum allowed size
when using Amazon CloudWatch logs or event notifications via Amazon SNS topics, consider refining your jobs with multiple stages by omitting the “transformation_ctx” parameters that differ from the source and target. Remember that a job bookmark comprises states for various components like sources, transformations, and targets. Additionally, when utilizing S3 connection types, adjusting the “maxFilesInBand” parameter can help minimize the bookmark state size. This parameter determines the maximum number of files retained during the last maxBand seconds; if the limit is surpassed, excess files will be excluded and addressed in the subsequent job execution. By default, “maxFilesInBand” is set to 1000, allowing the bookmark state to store up to 1000 S3 prefixes. This can be modified to 0 to resolve the issue.
Conclusion
In this article, we explored the drawbacks associated with AWS Glue job bookmarks. We discussed why bookmarks may fail when transferring data from JDBC-connected sources and examined the constraints related to the maximum size of job run states, along with potential solutions. I hope you found this post enlightening, and feel free to reach out with any questions.
If you enjoyed this content, consider following the Globalwork tech team on Medium, where we share actionable insights and tips from our experience in developing digital products.
Stay updated with my posts on Medium for more thought-provoking material. Don’t forget to clap for this publication and share it with your colleagues!
