Exploring AI's New Frontier: Communicate with Your Images
Written on
Chapter 1: Introduction to AI Image Communication
In recent times, you may have become familiar with AI-driven image generators like DALL-E 2, MidJourney, and Stable Diffusion. It's also likely that you've engaged with AI chatbots such as ChatGPT, Bard, and Bing Chat. However, have you ever considered an AI tool that not only chats with you but also facilitates communication with your images?
This is where LLaVA comes into play, an AI tool enabling users to upload images and converse about them.
Here’s an example:
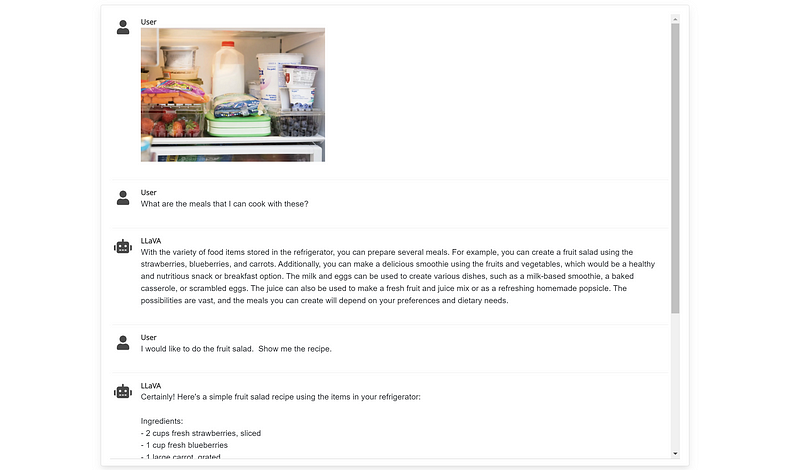
LLaVA: What Is It?
LLaVA, short for Large Language-and-Vision Assistant, represents a groundbreaking AI model that showcases advanced multimodal comprehension by merging image analysis with conversational abilities.
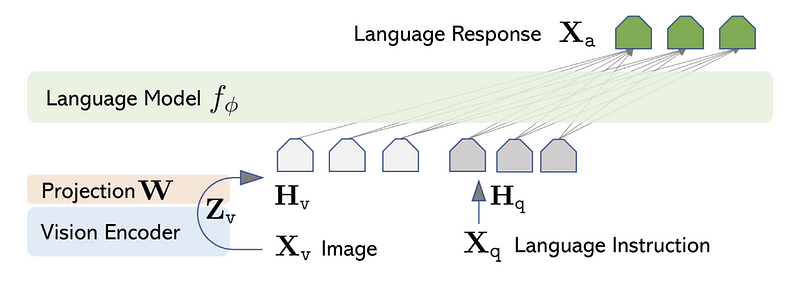
By leveraging the pre-trained CLIP ViT-L/14 visual encoder alongside the expansive language model Vicuna, LLaVA employs a projection matrix to connect these two elements.
Section 1.1: How to Use LLaVA
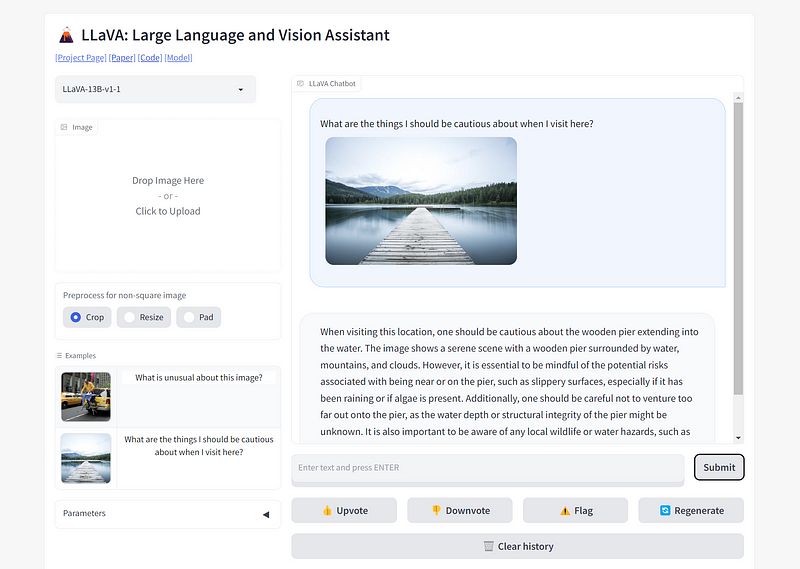
You can experience LLaVA yourself by visiting its Gradio Web app. Simply upload your image and ask the AI questions about it. For instance, you might inquire, “What does this image depict?” LLaVA will respond with a text-based answer.
Here’s an example of its functionality:
You'll be amazed at how well it interprets the image's content, even identifying famous artworks like the Mona Lisa, which highlights its impressive contextual understanding.
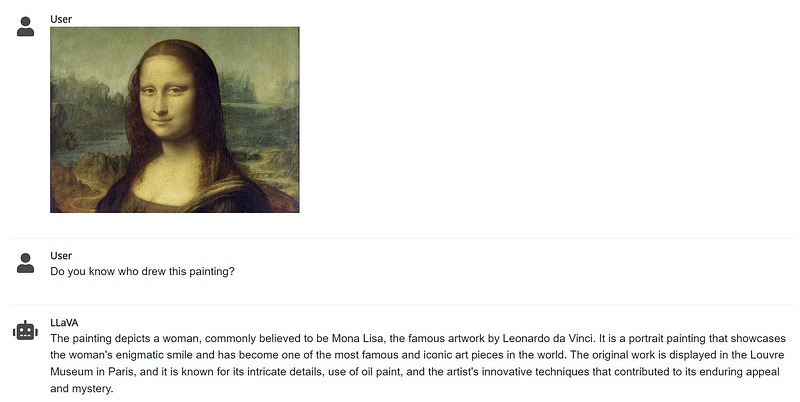
Section 1.2: Limitations and Capabilities
While LLaVA demonstrates remarkable abilities, it can also read text—though not flawlessly.
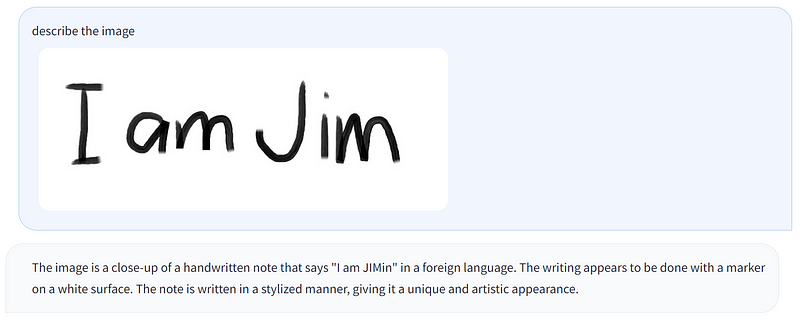
Although still in development, LLaVA has the potential to serve various functions.
Chapter 2: Potential Applications of LLaVA
The possibilities for LLaVA's applications are vast. Here are a few ideas:
- Assisting Individuals with Visual Impairments: LLaVA could provide textual descriptions of images, aiding those with visual impairments in better understanding their surroundings.
- Enhancing Social Media Engagement: Users might use LLaVA to create captions for their social media images, adding fun and functionality to their posts.
- Improving Image Search Engines: By supplying text descriptions of images, LLaVA could enhance the accuracy of image search engines, allowing for more relevant search results.
Final Thoughts
The trajectory of AI seems to be leaning toward a more integrated, multimodal approach, allowing different types of information to be interconnected seamlessly. With tools like LLaVA and GPT-4, we can anticipate a future where our interactions with technology become increasingly sophisticated and enriching.
However, is LLaVA superior to GPT-4? I am awaiting comparative results and will provide updates in future articles once I explore GPT-4’s multimodal features.
While LLaVA is still evolving, we can look forward to further advancements in this technology, enhancing our interactions with AI in meaningful ways.
Stay informed about the latest developments in the creative AI space by following the Generative AI publication.
To support my work on Medium and gain unlimited access, consider becoming a member through my referral link. Have a great day!
Video Demonstrations of LLaVA's Capabilities
In this video titled "ChatGPT Can Now Read Images - Here's 7+ Ways To Use It (INSANE)", you’ll discover the various functions of ChatGPT in reading and interpreting images.
The second video, "AI-GENERATED IMAGES USING ChatGPT STEP-BY-STEP TUTORIAL", provides a detailed guide on how to create AI-generated images using ChatGPT.